Performance comparison between Condy and other frameworks.
The benchmark source code can be found at condy-bench.
Test Environment:
- CPU: AMD Ryzen 9 7945HX with Radeon Graphics × 16
- Storage: SK Hynix HFS001TEJ9X115N (NVMe SSD, 1TB, PCIe 4.0 x4)
- Compiler: clang version 18.1.3
- OS: Linux Mint 22 Cinnamon
- Kernel: 6.8.0-90-generic
Baselines:
- libaio: The asynchronous file IO framework on Linux before io_uring.
- liburing: io_uring itself. Since it is not wrapped with coroutines, it is slightly less convenient to use.
- Asio: A popular IO framework in C++.
- Monoio: A Rust coroutine framework based on io_uring (has more stars than liburing on GitHub).
- Compio: Another Rust coroutine framework based on io_uring.
Sequential File Read
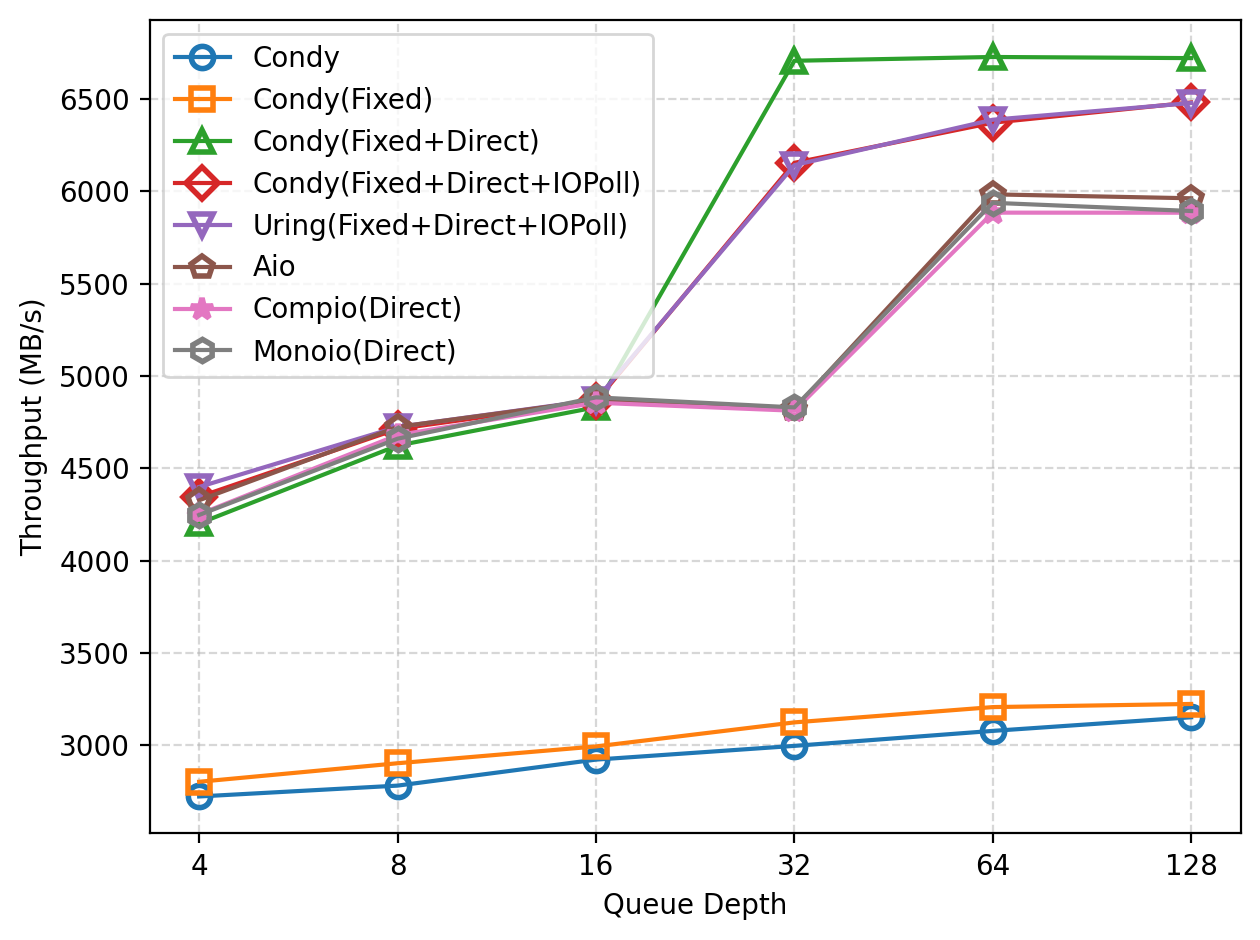
We tested the performance of Condy in 64KB sequential reads on an 8GB file, collected throughput data, and compared it with baseline implementations using libaio and liburing.
As shown in the figure, as the queue depth (number of concurrent tasks) increases, the read throughput gradually rises. When Direct IO is not enabled, Condy’s throughput is less than 3500MB/s. After registering files and buffers (marked as Fixed in the figure), Condy’s performance improves to some extent. With Direct IO enabled, Condy’s throughput increases significantly. At a queue depth of 4, Condy Direct IO is only slightly better than libaio. However, as the queue depth increases, Condy’s advantage becomes more pronounced, and at a queue depth of 32, throughput saturates (~6700MB/s). Further enabling IO Polling brings some throughput improvement at low queue depths, but as the queue depth increases, throughput is actually lower than with Direct IO alone. Monoio and Compio have lower throughput than libaio at all queue depths, and thus are also much lower than Condy. They did not fully utilize the performance potential of io_uring. Monoio performs slightly better than Compio.
In addition, Condy’s performance is roughly the same as the baseline program implemented with liburing under the same configuration.
Random File Read
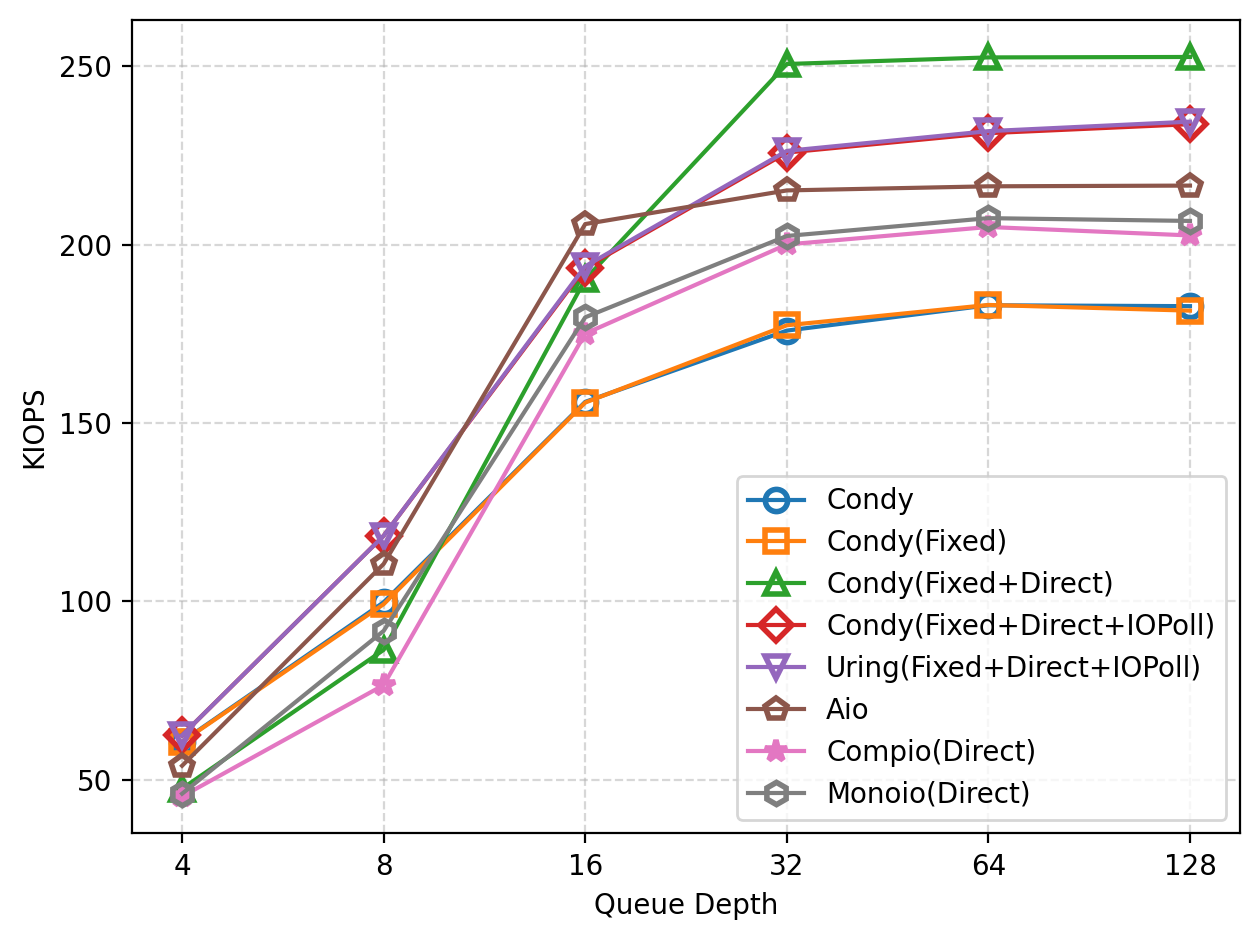
We tested the performance of Condy in 4KB random reads on an 8GB file, collected IOPS data, and compared it with baseline implementations using libaio and liburing.
As shown in the figure, as the queue depth (number of concurrent tasks) increases, the read IOPS gradually rises. When the queue depth is small (e.g., <=4), the performance of non-Direct IO is actually higher than that of libaio and Condy with Direct IO. Registering files and buffers on top of this provides a slight performance improvement, but the gain is not as significant as in sequential reads. When Direct IO is combined with IO Polling, Condy achieves optimal performance at small queue depths (<=8 in the figure).
At larger queue depths, Direct IO achieves better performance. When the queue depth reaches 16, libaio achieves the best performance but also reaches the saturation IOPS of the framework. Condy, however, can achieve even better IOPS as the queue depth continues to increase. In this scenario, plain Condy Direct IO achieves the best performance, while IO Polling is slightly worse but still better than libaio.
Monoio and Compio have lower throughput than libaio and Condy (with Direct IO) at all queue depths. The maximum performance gap between these frameworks and Condy is 50K IOPS (1.25x performance improvement). Monoio still performs slightly better than Compio.
Similarly, Condy’s performance is roughly the same as the baseline program implemented with liburing under the same configuration.
Echo Server
We tested the throughput of a TCP echo-server implemented with Condy and other methods as the number of connections increases on a single machine. Since the test is conducted locally, it does not fully reflect the performance of a real network card. However, it still allows us to observe the basic overhead brought by different frameworks on network IO.
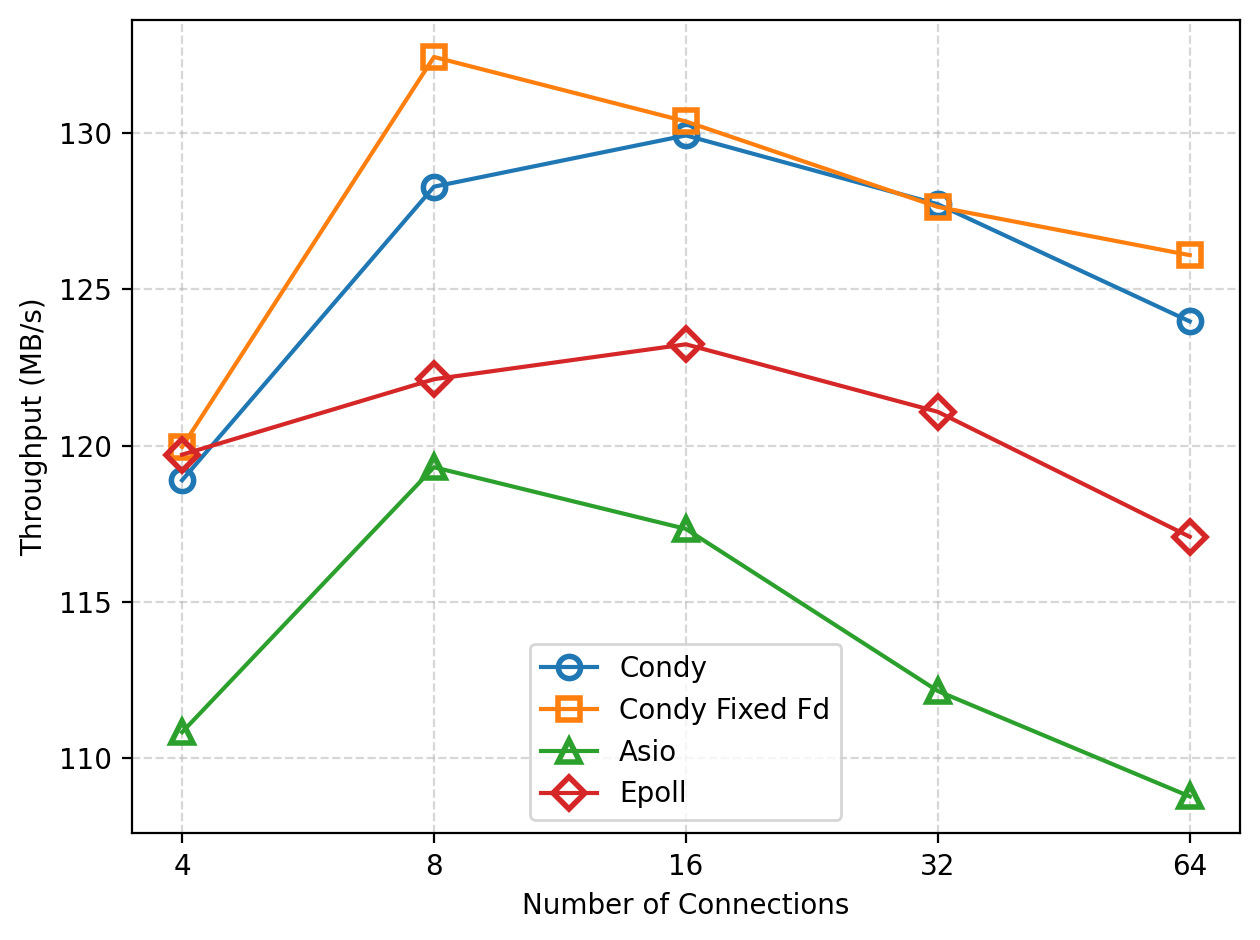
As the number of connections increases, the throughput first rises and then falls. The later decline is mainly due to contention caused by an increased number of client threads. As shown in the figure, Condy outperforms Asio and Epoll. With file registration, Condy can achieve a small additional performance gain.
Channel
We compared the performance of Condy, Asio, Monoio, and Compio Channels by varying the number of messages sent and the number of Channels, and measuring the total time taken. (Monoio and Compio use futures::channel::mpsc.)
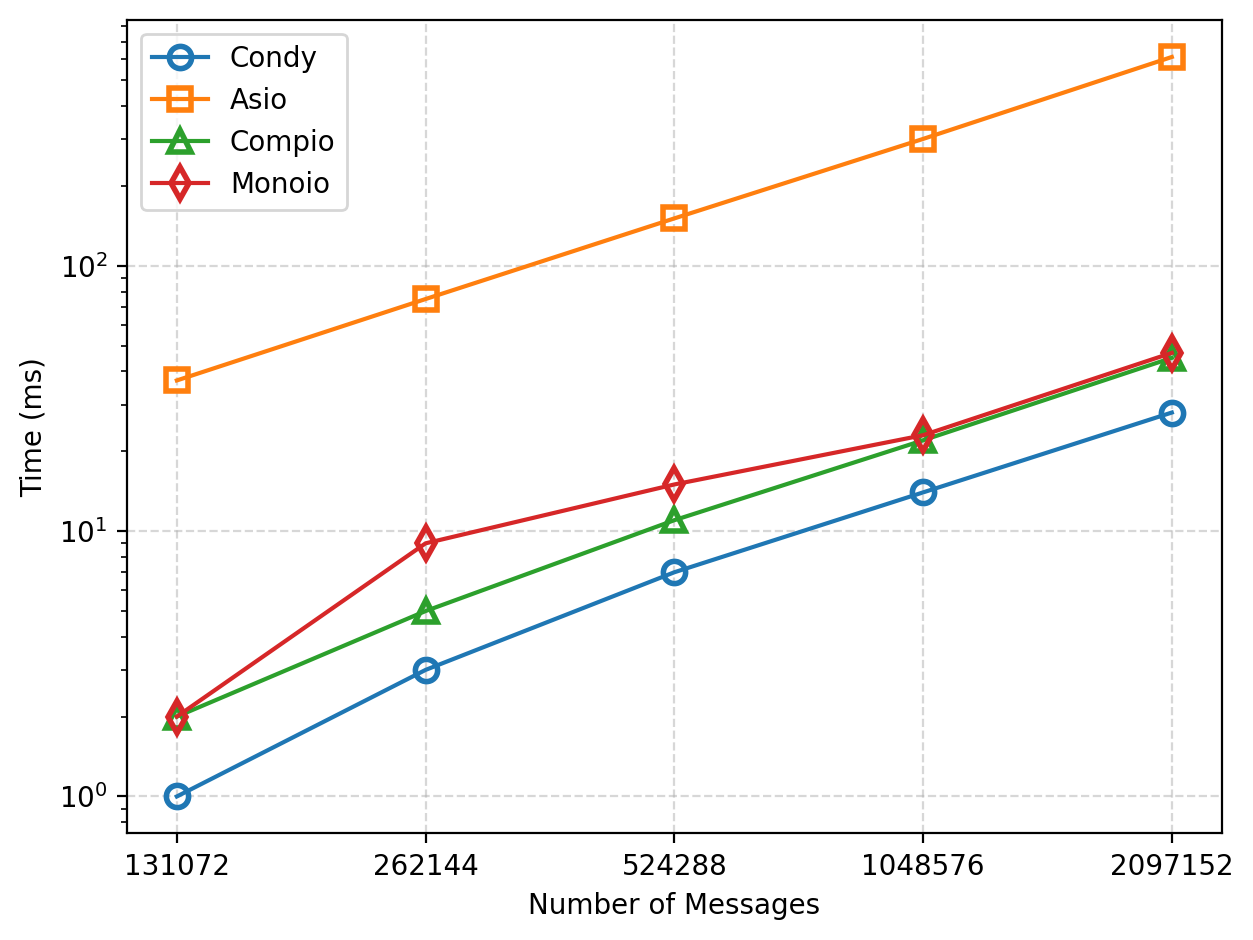
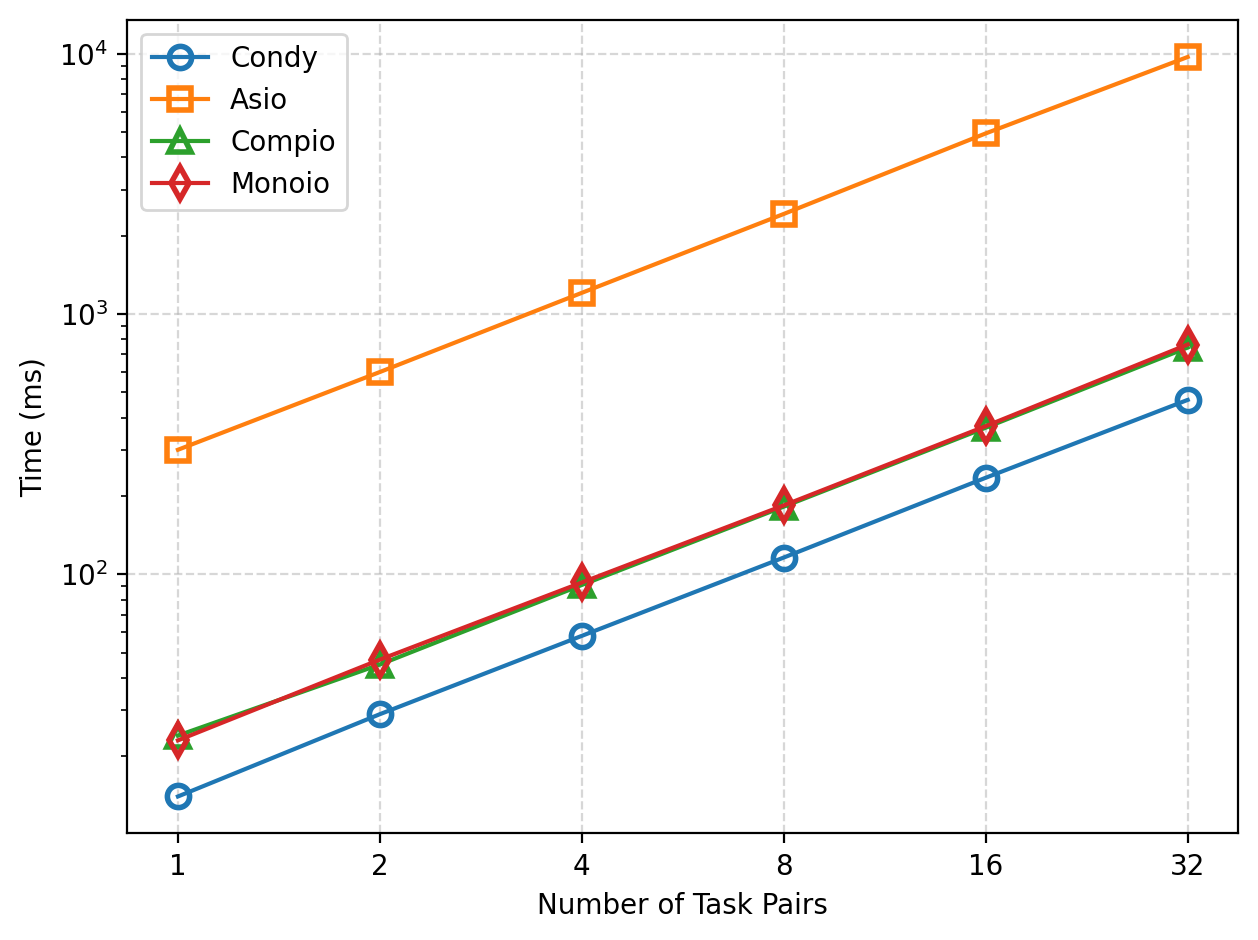
As shown in the figures, as the number of messages and concurrent tasks increases, the total time for these frameworks increases linearly. In terms of execution time, Condy achieves a 20x performance improvement over Asio. Compared to Monoio and Compio, there is also a 1.6x performance improvement.
Coroutine Spawn
We compared the efficiency of Condy, Asio, Monoio, and Compio in coroutine creation by varying the number of coroutines created and measuring the total time taken.
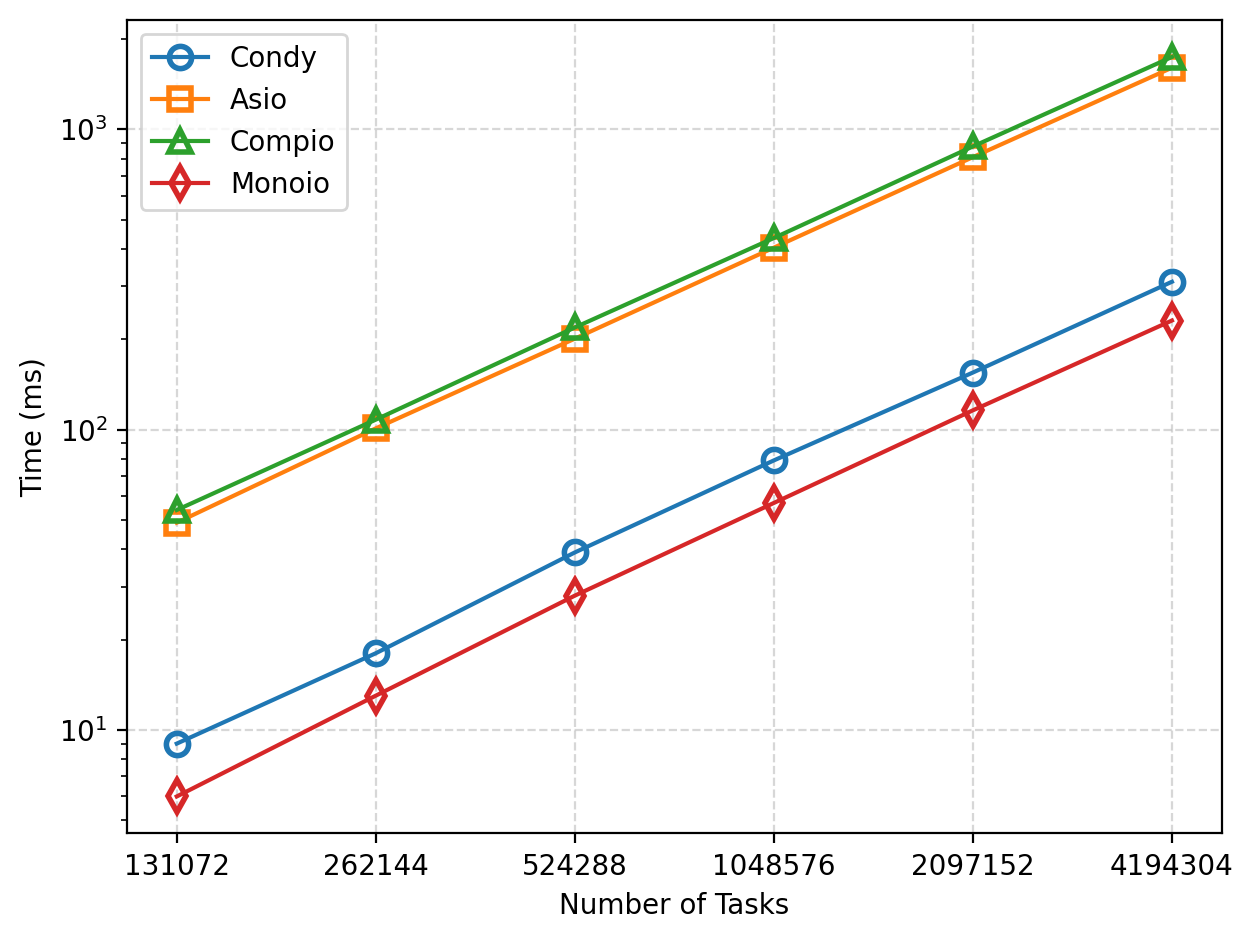
As shown in the figure, as the number of coroutines increases, the total time for these frameworks increases linearly. In terms of execution time, Condy achieves a 5x performance improvement over Asio and Compio. Condy's performance is slightly inferior to Monoio. However, the average creation time per coroutine for Condy only increases by 19ns (compared to 55ns for Monoio).
Coroutine Switch
We compared the efficiency of Condy, Asio, and Monoio in coroutine context switching by repeatedly switching coroutines and measuring the total time taken. (Monoio use futures_lite::future::yield_now. Compio was not included in this comparison due to excessive time consumption in this test.)
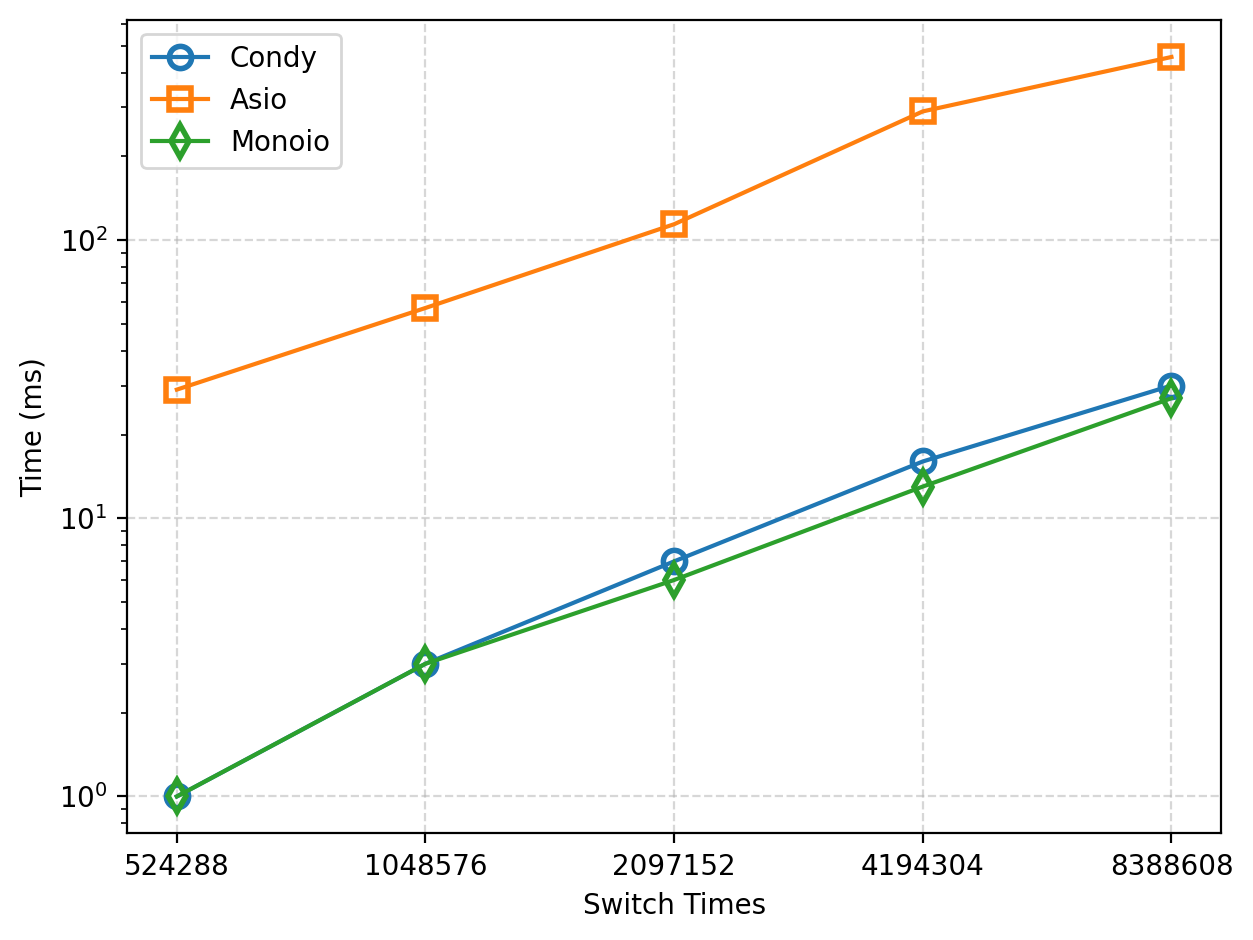
As shown in the figure, as the number of switches increases, the total time for these frameworks increases linearly. In terms of execution time, Condy achieves a 15x performance improvement over Asio. It also achieves performance results close to Monoio, with the maximum difference per switch not exceeding 0.8ns (about 3ns per switch).